Designing Robust AIML/GenAI Applications: Key Attributes for Success
Artificial Intelligence and Generative AI are revolutionizing how we build applications. However, designing successful AI-powered systems requires more than just throwing together a model and an API. Three critical architectural patterns — batching, fan-out, and scheduling — form the backbone of scalable AI systems. It demands careful consideration of system design principles to ensure efficiency, scalability, and reliability.
This blog post will explore critical attributes and features that contribute to a well-designed AIML/GenAI application, providing examples, relevant tools, and guidance on when to apply them.

1. Batching: Optimizing Efficiency and Managing Trade-Offs
Batching is the process of grouping multiple individual requests into a single operation for processing. This can significantly improve efficiency by reducing overhead and optimizing resource utilization. Batching refers to aggregating multiple units of work (requests, records, inferences) and processing them together rather than individually. This approach optimizes latency vs. throughput, reduces overhead, and increases system efficiency.
How it Works: Instead of processing each request sequentially, the system accumulates requests until a certain batch size is reached or a time interval expires. Then, the entire batch is processed as a single unit.
Why It Matters in AI/ML
- ML Inference: Sending a batch of records to a model instead of one at a time allows the GPU/TPU to utilize parallel computing.
- Database Writes: Batch inserts reduce round-trips and I/O operations.
- API Calls: Aggregated requests reduce network calls and improve performance.
🛠️ Tools & Examples
- TensorFlow/PyTorch: Native support for batch inferences.
- Apache Beam / Spark: Large-scale batch data processing.
- FastAPI + Celery: Queue multiple API requests and batch-process them.
- Airflow DAGs: Schedule and run batch ETL or ML training pipelines.
Benefits:
- Improved Throughput: Reduces the overhead associated with processing individual requests, leading to higher throughput.
- Reduced Latency Variation: Can smooth out latency fluctuations by processing requests in batches.
- Optimized Resource Utilization: Allows for more efficient use of resources like database connections and API calls.
Examples:
- API Calls: When handling a high volume of API requests, batching can reduce the number of network round trips and improve overall API performance. Tool: Python’s asyncio library for asynchronous batch processing.
- Database Writes: Batching database writes can reduce the load on the database and improve write throughput. Accumulating user activity logs in 5-second windows before bulk insertion. Tool: Database libraries like SQLAlchemy (Python) offer batch insert/update functionality.
- ML Inference: For ML inference, batching multiple input samples into a single request can significantly improve GPU utilization and reduce inference latency. Tool: TensorFlow Serving, TorchServe. Processing 100 images in a single batch reduces GPU memory transfers by 100x compared to individual requests.
Trade-offs:
- Increased Latency: Batching introduces a delay while waiting for the batch to fill up, potentially increasing individual request latency.
- Complexity: Implementing batching requires careful consideration of batch size, timeout intervals, and error handling.
Example Trade-Off:
The tradeoff lies between waiting for multiple API calls and to serve. Waiting in long queue for multiple calls is not appropriate so we have to chose the ideal point.
When to Use: Batching is most beneficial when dealing with high volumes of similar requests where a small increase in latency is acceptable in exchange for improved throughput and resource utilization.
- High-throughput requirements (>1k requests/sec)
- Resource-constrained environments (GPUs/TPUs)
- Operations with fixed overhead costs (DB connections, GPU warmup)
- Model inference on large datasets
- Delayed/periodic processing (e.g., batch scoring every hour)
- Reducing cost in serverless setups (e.g., batch DB writes)
2. Fan-Out: Achieving Parallel Processing and Failure Isolation
Fan-out is a design pattern that involves distributing a single task or request to multiple parallel workers for processing. This enables parallel processing, improves performance, and provides failure isolation.
How it Works: A single request is divided into smaller subtasks, and each subtask is assigned to a different worker for processing. The results from the workers are then aggregated to produce the final result.
🧠 Why It Matters in AI/ML
- Real-time Data Pipelines: When data ingestion triggers multiple processing workflows.
- Multimodal AI: A user query could require processing via text, vision, and audio pipelines simultaneously.
- GenAI Agents: Prompt can be sent to multiple LLMs or tools in parallel (e.g., search + summarization + extraction).
🛠️ Tools & Examples
- AWS SNS + Lambda: Event triggers multiple functions for parallel execution.
- Apache Kafka: Publish/subscribe model enables fan-out across consumers.
- Ray / Dask: Python-native parallel execution libraries for ML workloads.
- LangChain Agents: Tool-calling and parallel chains in GenAI workflows.
- Message Brokers: Apache Kafka, AWS SNS
- Orchestration: Apache Airflow, Inngest
- Cloud Services: AWS Lambda@Edge, Google Cloud Tasks
Benefits:
- Parallel Processing: Allows for concurrent execution of tasks, significantly reducing processing time.
- Failure Isolation: If one worker fails, it doesn’t necessarily affect the entire process.
- Scalability: Easily scale the processing capacity by adding more workers.
Examples:
- Event-Driven Architectures: In event-driven architectures, a fan-out pattern can be used to distribute incoming events to multiple consumers for parallel processing. Tool: Apache Kafka, RabbitMQ.
- Image Processing: Large images can be divided into smaller tiles, and each tile can be processed by a different worker. Tool: Celery (Python), AWS Lambda.
- Data Analysis: Complex data analysis tasks can be broken down into smaller subtasks and distributed to multiple workers for parallel processing. Tool: Apache Spark.
- User uploads video → Split into frames (fan-out)
- Parallel frame processing → 10 workers analyze facial expressions
- Combine results → Generate emotion timeline
Example for genAI:
Multiple GenAI API endpoints can be used and connected so the user experience will be less, where fan out will be very helpful.
Trade-offs:
- Increased Complexity: Implementing fan-out requires careful coordination and management of parallel workers.
- Synchronization Overhead: Aggregating the results from multiple workers can introduce synchronization overhead.
When to Use: Fan-out is ideal for tasks that can be easily divided into independent subtasks and processed in parallel. It is particularly useful for improving performance and scalability in computationally intensive applications.
- Independent sub-tasks (image processing, feature extraction)
- Mixed workload types (CPU vs GPU-bound tasks)
- Fault isolation requirements (critical vs non-critical paths)
- Event-driven systems needing high concurrency
- Workflow isolation for error containment (e.g., retry failing branches independently)
- Large GenAI pipelines where components (e.g., chunking, summarization) work concurrently
3. Scheduling: Automating Tasks and Managing Workflows
Scheduling is the process of automating the execution of tasks at specific times or intervals. This is essential for managing time-based operations, retries, and complex workflows.
How it Works: A scheduler is configured to execute a task or a workflow at a predefined time or interval. The scheduler monitors the system and triggers the task execution when the specified conditions are met.
Benefits:
- Time-Based Execution: Allows for the automation of tasks that need to be executed at specific times (e.g., daily backups, monthly reports).
- Delayed Jobs: Enables the execution of tasks that can be deferred to a later time (e.g., sending welcome emails after user registration).
- Retries and Error Handling: Facilitates automatic retries for failed tasks, improving reliability and fault tolerance.
- Workflow Management: Provides a mechanism for orchestrating complex workflows by scheduling the execution of individual tasks in a specific order.
🧠 Why It Matters in AI/ML
- Data Freshness: Regular ETL for model input data.
- Model Retraining: Periodic re-training to avoid model drift.
- Retry Mechanisms: Handle failed jobs or delayed processing in queues.
🛠️ Tools & Examples
- Apache Airflow / Prefect: Declarative workflow orchestration and time-based DAGs.
- Kubernetes CronJobs: Native scheduling in container environments.
- Celery Beat: Periodic task scheduling with Celery workers.
- Unix Cron: Classic and lightweight option for time-based jobs.
- AWS EventBridge + Lambda
Examples:
- Cron Jobs: Cron jobs are a fundamental tool for scheduling tasks in Unix-like operating systems. Tool: cron (Linux/macOS).
- Delayed Jobs: Delayed job queues allow you to defer the execution of tasks to a later time. Tool: Celery (Python), Redis Queue (Python).
- Workflow Engines: Workflow engines provide a framework for defining and executing complex workflows. Tool: Apache Airflow, Prefect.
- 04:00 Daily: Retrain recommendation models
- Every 15min: Process accumulated sensor data
- Exponential Backoff: Failed API call retries (1s → 2s → 4s)
Trade-offs:
- Complexity: Managing scheduling configurations and dependencies can be complex, especially for large and intricate workflows.
- Resource Management: Improperly configured schedules can lead to resource contention and performance issues.
When to Use: Scheduling is essential for automating tasks, managing workflows, and ensuring the reliable execution of time-sensitive operations. It is particularly useful for tasks that require retries, error handling, or complex dependencies.
- Periodic bulk operations (daily reports)
- Resource optimization (off-peak processing)
- Pipeline dependencies (B must follow A)
- Scheduled inference, retraining, or ETL jobs
- Retry mechanisms for failed or delayed ML tasks
- Automation of periodic GenAI content generation or checks
🧭 Best Practices and Tips
A real-world GenAI-based document summarization app might look like this:
- Batching: Collect documents uploaded in the last 30 minutes and send them in one request to a summarization model.
- Fan-Out: For each document, generate summaries via three different LLMs to pick the best response.
- Scheduling: Use Airflow to trigger the entire pipeline every hour and log errors for retry.

4. Bonus: Monitoring and Observability
While not directly involved in processing, these are critical design consideration for AIML/GenAI systems. Robust monitoring and observability are essential for understanding system behavior, identifying performance bottlenecks, and diagnosing issues.
Modern AI systems combine these patterns — batch incoming requests, fan-out to specialized model variants, and schedule periodic model updates. The optimal mix depends on your latency SLA (100ms vs 10s), throughput needs, and error recovery requirements.
Monitoring Essentials:
- Batch Fill Rate (80–95% utilization)
- Fan-Out Distribution Evenness
- Schedule Drift Detection
Key Metrics to Monitor:
- Model Performance: Accuracy, precision, recall, F1-score, AUC.
- Inference Latency: Time taken to generate predictions.
- Resource Utilization: CPU, memory, GPU utilization.
- Error Rates: Number of failed requests, exceptions, and errors.
- Data Drift: Changes in the distribution of input data over time.
Tools:
- Prometheus: A popular open-source monitoring system for collecting and storing metrics.
- Grafana: A data visualization tool for creating dashboards and monitoring system performance.
- Jaeger: A distributed tracing system for tracking requests as they flow through the system.
Example Scenario: Building a Real-Time Image Classification Service
Let’s consider an example of building a real-time image classification service:
- Batching: Batch multiple incoming image requests into a single inference request to improve GPU utilization.
- Fan-Out: Distribute image preprocessing tasks (e.g., resizing, normalization) to multiple workers for parallel processing.
- Scheduling: Schedule periodic model retraining jobs to maintain model accuracy and adapt to changing data distributions.
- Monitoring: Monitor model performance, inference latency, and resource utilization to identify and address potential issues.
When implementing, consider:
- Batch Size: Too small → underutilization, Too large → memory bloat.
- Fan-Out Degree: Over-parallelization causes resource contention.
- Schedule Density: Cluster overheating from cron storming.
Advanced Patterns and Considerations
Circuit Breaker Pattern
Prevent cascading failures in distributed ML systems by monitoring service health and automatically failing fast when downstream services are unavailable.
Bulkhead Pattern
Isolate critical resources (GPU memory, database connections) to prevent resource exhaustion from affecting the entire system.
Load Balancing Strategies
- Round-robin: Simple distribution across model replicas
- Least connections: Route to least busy model server
- Weighted routing: Direct traffic based on model server capacity
- Geographic routing: Route to nearest model deployment
Monitoring and Observability
Implement comprehensive logging, metrics, and tracing:
- Model prediction latency and throughput
- Resource utilization (CPU, GPU, memory)
- Error rates and failure patterns
- Data drift detection
- Model performance degradation alerts
Choosing the Right Pattern
The selection of these patterns depends on your specific requirements:
High Throughput + Acceptable Latency → Batching Perfect for offline batch predictions, ETL pipelines, and scenarios where you can trade slight latency increases for massive throughput gains.
Parallel Processing + Fault Tolerance → Fan-Out Ideal for ensemble models, large dataset processing, and distributed inference where failure isolation is crucial.
Automation + Reliability → Scheduling Essential for MLOps pipelines, model maintenance, data processing workflows, and any time-based automation needs.
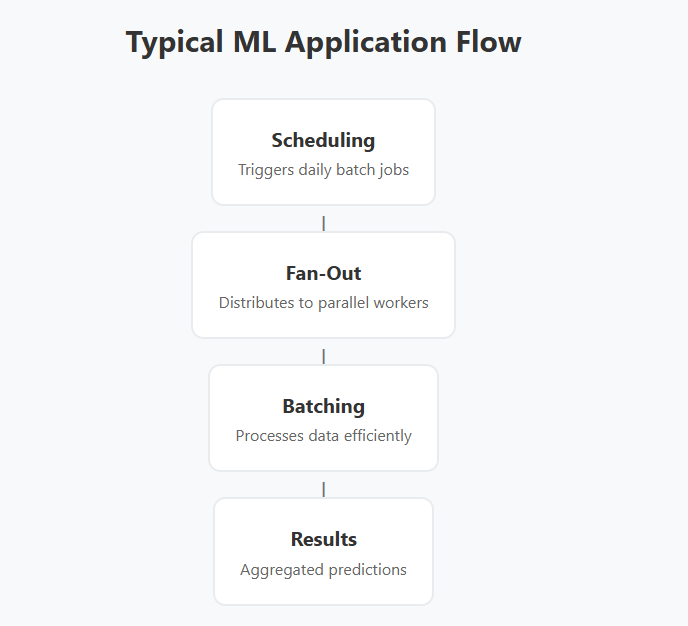
These patterns often work together in production systems. A typical ML application might use scheduling to trigger daily batch inference jobs that employ batching for efficient processing and fan-out for parallel execution across multiple model replicas.
The key to successful AI/ML system design lies in understanding your specific requirements around latency, throughput, reliability, and scalability, then thoughtfully combining these patterns to create robust, production-ready applications that can handle real-world demands.
Conclusion
Designing robust and scalable AIML/GenAI applications requires careful consideration of system design principles. By leveraging techniques like batching, fan-out, and scheduling, and by implementing robust monitoring and observability, you can build AI-powered systems that are efficient, reliable, and capable of delivering valuable insights and experiences. Remember to choose the right tools for the job and to adapt your design to the specific requirements of your application.
System design in AI/ML and GenAI applications must go beyond model performance. By incorporating principles like batching for efficiency, fan-out for scalability and resilience, and scheduling for automation and reliability, your application can be robust, scalable, and production-grade.
Whether you’re processing millions of records or building interactive GenAI tools, mastering these architectural features will help you deliver high-performance AI systems at scale.
#AIML #GenAI #SystemDesign #AISystemDesign #Batching #FanOut #Scheduling #Scalability #PerformanceOptimization #AIOps #DataEngineering #TechBlog #AIInsights #AginexAI



Comments
Post a Comment