Leaner, Faster, Smarter: Unpacking AI Model Compression Techniques
Modern Artificial Intelligence, particularly Large Language Models (LLMs) and complex deep learning systems, is incredibly powerful. These models can write code, generate stunning images, and understand nuanced language. But this power comes at a cost: size. State-of-the-art models can have billions, even trillions, of parameters, demanding massive computational resources, significant energy, and substantial storage.
This heft creates barriers. Deploying these behemoths on smartphones, edge devices, or even cost-effectively in the cloud becomes a major challenge. Latency creeps in, user experience suffers, and the energy footprint grows.
Enter Model Compression and Optimization: a suite of techniques designed to shrink these AI giants without crippling their intelligence. Model compression and optimization techniques bridge this gap, enabling faster, cheaper, and greener AI. Let’s explore the key methods, their pros and cons, and how they’re reshaping industries. The goal is to create leaner, faster models that are more practical, accessible, and sustainable. Done right, these techniques can dramatically reduce AI compute costs (sometimes by as much as 80%!), accelerate inference speeds (potentially 6x or more!), and critically, enable powerful AI on low-power edge devices.
Let’s explore why this is crucial and dive into the most common techniques.
Why Do We Need to Compress AI Models?
The drive to slim down AI models isn’t just academic. It has tangible benefits:
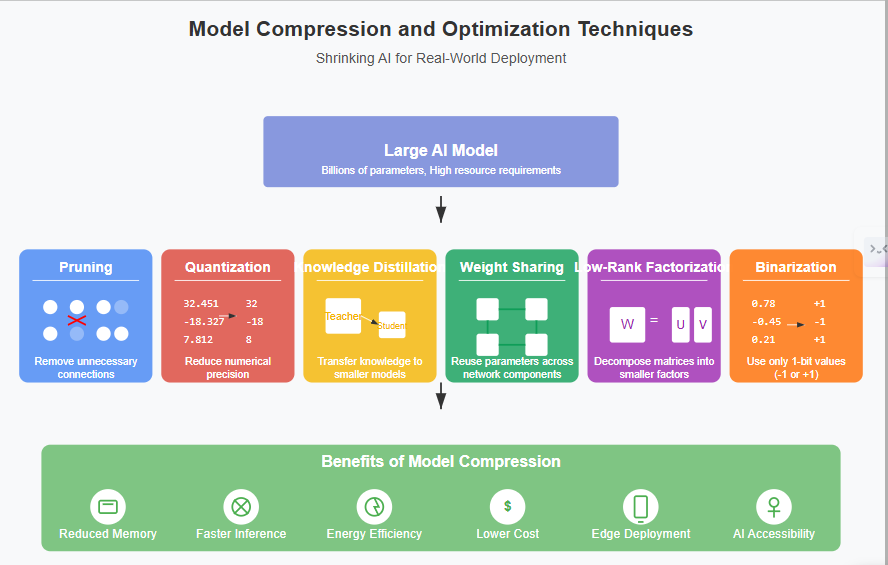
- Resource Efficiency: Smaller models mean less memory (RAM) and storage are needed, making deployment feasible on devices with limited hardware, like smartphones, IoT sensors, wearables, and embedded systems.
- Cost Reduction: Less compute means lower cloud bills. Reduced storage needs also cut costs. This democratization makes advanced AI more affordable for businesses and researchers.
- Faster Inference: Smaller models generally run faster. This is critical for real-time applications like autonomous driving, responsive chatbots, live video analysis, and interactive virtual assistants. Low latency = better user experience.
- Energy Savings: Less computation translates directly to lower power consumption. This is vital for battery-powered devices and contributes to more sustainable “Green AI” practices.
- Accessibility & Reach: Making models smaller allows advanced AI capabilities to reach more users and devices, regardless of high-end hardware access or fast internet connections (especially for on-device AI).
Key Model Compression Techniques Explained
Several techniques can be used, often in combination, to achieve significant compression and optimization. Here are some of the most prominent:
1. Pruning: Trimming the Fat
Explanation: Imagine carefully trimming unnecessary branches from a bonsai tree to maintain its health and shape. Pruning in AI involves identifying and removing redundant or unimportant connections (weights) or even entire neurons/structures within the neural network that contribute little to the final output.
How it Works: Weights with small magnitudes (close to zero) are often considered less important. Pruning algorithms identify these weights and permanently set them to zero. More advanced techniques might assess neuron activation patterns or use sensitivity analysis. This creates sparsity in the model.
- Train the full model to completion
- Identify unimportant weights based on magnitude, activation patterns, or gradient-based metrics
- Remove these weights by setting them to zero
- Fine-tune the pruned model to recover accuracy
Types:
- Unstructured pruning (removes individual weights)
- Structured pruning (removes neurons, filters, or layers)
Pros:
- Can significantly reduce the number of parameters (model size).
- If done carefully (structured pruning), can lead to speedups, especially with hardware/libraries supporting sparse computations.
- Reduces model size by up to 90%.
- Speeds up inference (e.g., 6x faster ResNet-507).
- Works post-training or during training.
Cons:
- Can negatively impact accuracy if pruned too aggressively.
- Unstructured pruning (random zeroed weights) might not yield speedups without specialized hardware/software.
- Finding the right balance between compression and accuracy often requires iterative tuning.
- Requires careful fine-tuning.
Use Cases: Deploying models on devices with strict memory limits; reducing the footprint of large models where slight accuracy trade-offs are acceptable.
Pruning ResNet models for faster image classification on mobile devices.
Edge Devices: A pruned YOLO model detects objects in real-time on drones, using 60% less memory.
2. Quantization: Speaking with Fewer Bits
Explanation: Think of representing a color. You could use millions of shades (like high-precision numbers, e.g., 32-bit floating point, FP32) or a smaller palette (like lower-precision numbers, e.g., 8-bit integers, INT8). Quantization reduces the numerical precision used to store model weights and/or activations.
How it Works: It maps high-precision floating-point numbers (e.g., FP32) to lower-precision representations (e.g., FP16, INT8, or even fewer bits). This dramatically reduces the memory required for each parameter.
- Analyze the model’s weight distribution
- Map the original floating-point values to a reduced bit-width representation
- Adjust computation to work with lower precision
- Apply calibration to minimize information loss
Types:
- Post-Training Quantization (PTQ) — Applied after training.
- Quantization-Aware Training (QAT) — Model is trained with quantization in mind.
Pros:
- Significant reduction in model size (e.g., FP32 -> INT8 is a 4x reduction).
- Major potential for faster inference, especially on hardware with optimized low-precision instructions (like GPUs and TPUs).
- Lower power consumption.
- Accelerates computation (e.g., 2x faster inference).
- Supported by TensorFlow Lite, PyTorch Mobile.
- Significant memory and latency improvements
- Well-supported in mobile/edge ML toolkits (e.g., TensorFlow Lite, ONNX)
Cons:
- Almost always involves some loss of accuracy, though techniques like Quantization-Aware Training (QAT) can mitigate this.
- Sensitivity varies across models; some parts might be more affected by lower precision than others.
- Accuracy drops (e.g., 8–10% in vision tasks).
- Hardware-specific compatibility issues.
Use Cases: Edge AI on smartphones, IoT devices; accelerating inference in data centers; reducing memory bandwidth bottlenecks. This is one of the most widely used and impactful techniques.
Deploying quantized BERT models for NLP tasks on Android smartphones.
Smartphones: WhatsApp uses 8-bit quantization to run speech-to-text models locally.
3. Knowledge Distillation: Learning from a Master
Explanation: Imagine a large, experienced “teacher” model training a smaller, faster “student” model. The student learns not just the correct answers (hard labels) but also how the teacher arrives at its conclusions by mimicking its output probabilities (soft labels or logits).
How it Works: The large, pre-trained teacher model processes data, and its output layer’s probabilities (which contain richer information than just the final prediction) are used as part of the loss function to train the smaller student model.
- Train a large teacher model to high accuracy
- Train a smaller student model to mimic the teacher’s outputs
- Use “soft targets” (probability distributions) rather than hard class labels
- Balance between matching teacher outputs and optimizing for ground truth
Pros:
- Can transfer complex knowledge from a large model to a much smaller one, often preserving accuracy remarkably well.
- The student model benefits from the teacher’s “generalization” capabilities.
- Preserves 95%+ accuracy with 10x smaller models.
- Ideal for task-specific deployments.
Cons:
- Requires having a well-trained (and often expensive) teacher model available.
- The training process can be more complex than standard training.
- The student might not capture every subtle nuance of the teacher.
- Time-consuming knowledge transfer.
Use Cases: Creating highly specialized, efficient models derived from large general-purpose models; deploying complex AI capabilities on resource-constrained hardware.
Distilling a GPT-style transformer into a smaller chatbot that runs on laptops without GPUs.
Healthcare: Distilled BERT models diagnose diseases from medical notes on low-power tablets.
4. Weight Sharing: Recycling Parameters
Explanation: Reuses weights across layers to reduce redundancy. Groups of weights are forced to use the same value, reducing the total number of unique weights that need storing. Think of it like using a limited set of “stamps” instead of drawing every detail uniquely.
How it works: Applies shared filters in CNNs, cutting parameters by 50%+.
- Identify parameters that can be shared across different parts of the network
- Enforce parameter sharing during training
- Store only unique parameters rather than duplicates
Pros:
- Lowers memory usage significantly.
- Improves generalization in some cases.
- Often used in combination with quantization
Cons:
- Limits model flexibility.
- Can impact performance if grouping is too aggressive
- Requires specialized training or conversion
Use Case:
- Autoencoders: Weight-shared models compress video feeds for security cameras.
- CNN models in image processing apps where model footprint is critical.
5. Low-Rank Factorization: Simplifying Math
Explanation: Decomposes large weight matrices into smaller, lower-rank matrices. This leverages linear algebra properties to approximate the original matrix with fewer parameters, particularly effective for fully connected layers.
How it works: Uses techniques like Singular Value Decomposition (SVD).
- Analyze weight matrices for redundancy
- Decompose each large matrix into products of smaller matrices
- Replace original layers with factorized versions
- Fine-tune the factorized model
Pros:
- Reduces parameters by 70% in recommendation systems.
- Maintains accuracy with proper tuning.
- Useful for dense layers and attention heads
Cons:
- Computationally intensive to find optimal rank.
- Complexity in determining the right rank
- May not benefit all layers equally
Use Case:
- E-commerce: Amazon uses low-rank factorization to shrink product recommendation models.
6. Binarization: The Extreme Diet
Explanation: Represents weights as 1-bit values (-1 or 1). An extreme form of quantization where weights and sometimes activations are constrained to only two values, typically +1 and -1 (or 0 and 1). This offers maximum compression and potential for extremely fast bitwise operations but often comes with a significant accuracy hit.
How it works: Sacrifices precision for radical compression.
- Replace floating-point operations with binary operations
- Use specialized training techniques to handle binary constraints
- Leverage bit-wise operations for extremely fast computation
Pros:
- 32x smaller models (32-bit → 1-bit).
- Enables AI on microcontrollers.
- Huge reductions in model size and power consumption.
- Can enable inference on microcontrollers.
Cons:
- Accuracy plummets for complex tasks.
- Severe accuracy loss in complex models.
- Suitable mostly for lightweight tasks.
Use Case:
- IoT: Binary sensors detect factory machine faults using 100KB models.
- Ultra-efficient models for wearables and embedded devices.
7. Hybrid Approaches: Best of All Worlds
Often, the best results come from combining multiple techniques — e.g., pruning a model first, then quantizing it, or using distillation to train a pruned/quantized student.
Pros:
- Leverages the strengths of multiple techniques.
- Can achieve better compression and performance than individual methods.
Cons:
- Can be complex to implement and optimize.
- May require additional computational resources.
Combining techniques amplifies benefits:
- Distillation + Low-Rank: GPT-3 compressed 10x for faster ChatGPT responses.
- Pruning + Quantization: First remove unnecessary connections, then reduce precision of remaining weights. eg. A ConvNeXt model shrank by 90% with 3.8% accuracy gain.
- Distillation + Quantization: Train a smaller student model, then quantize it for further compression
- Factorization + Pruning: Apply low-rank factorization to layers, then prune the factorized model
Example:
- MobileNet (CNN for mobile) uses depth wise separable convolutions + quantization.
- DistilBERT combines distillation + pruning for efficient NLP.
- A hybrid compressed model for autonomous drone navigation: distilled model + quantized layers + pruned convolution filters.
Real-World Example
MobileBERT combines architecture redesign, knowledge distillation, and quantization to create a model that’s 4.3x smaller and 5.5x faster than BERT-base while retaining 99.25% of its performance on NLP benchmarks.
Why Compress Models?
- Cost: Training GPT-3 cost $4.6M-compression slashes cloud bills.
- Speed: Real-time translation on phones (e.g., Google Translate).
- Sustainability: 50% less energy use in data centers.
- Accessibility: Farmers use offline AI pest detectors in rural India.
Benefits vs. Challenges: The Balancing Act
Overall Benefits:
- Massive Efficiency Gains: As mentioned, significant reductions in compute cost, storage, and power usage.
- Blazing Fast Inference: Reduced latency leading to better real-time performance.
- Democratization of AI: Enabling advanced AI on everyday devices and for organizations with limited budgets.
- Improved Sustainability: Lowering the energy footprint of AI operations.
Overall Challenges:
- Accuracy Trade-off: Most compression techniques risk reducing model accuracy. The key challenge is minimizing this loss.
- Complexity & Expertise: Implementing and tuning these techniques effectively requires specialized knowledge and can be complex.
- Hardware/Software Compatibility: Some techniques (like structured pruning or specific quantization levels) need specific hardware support or optimized software libraries (like TensorRT, ONNX Runtime, TensorFlow Lite) to realize their full speed benefits.
- Tuning Effort: Finding the optimal compression strategy and parameters for a specific model and task often requires significant experimentation.
Challenges to Overcome
- Accuracy Trade-offs: Balancing size and performance.
- Hardware Limits: Not all chips support 4-bit quantization.
- Complexity: Managing hybrid methods requires expertise.
- Dynamic Workloads: Adapting compression for real-time data shifts.
The Future of Model Compression
From smartwatches predicting heart issues to satellites analyzing crops, compressed models are democratizing AI. As frameworks like TensorFlow Lite and PyTorch Mobile bake in these techniques, expect even your fridge to run GPT-6 someday-efficiently. As AI continues to advance, model compression is becoming increasingly important. Some emerging trends include:
- Hardware-aware compression: Optimizing models specifically for target hardware
- Automated compression pipelines: Tools that automatically select and apply the best compression strategies
- Neural architecture search for efficiency: Discovering inherently efficient architectures
- Specialized accelerators: Hardware designed specifically for compressed models
Conclusion: Making AI Practical
Model compression and optimization are no longer niche topics; they are essential for the practical deployment and scaling of artificial intelligence. As models continue to grow in complexity, techniques like pruning, quantization, and knowledge distillation will be crucial for bridging the gap between cutting-edge research and real-world applications. By making AI leaner, faster, and more accessible, these methods pave the way for a future where intelligent systems are seamlessly integrated into our devices and workflows, efficiently and sustainably.
By understanding and applying techniques like pruning, quantization, distillation, weight sharing, factorization, and binarization, developers can dramatically reduce model size, improve inference speed, and lower deployment costs.
The most successful applications typically combine multiple compression approaches tailored to specific use cases and hardware targets. As compression techniques mature and tooling improves, we can expect AI to become more accessible and efficient across a wide range of devices and applications.
The ultimate goal is clear: bringing state-of-the-art AI capabilities to every device, regardless of its computational resources, while minimizing energy consumption and maximizing performance.
For detailed insights, please visit my blog at
Explore more of my articles on Medium at https://medium.com/@ajayverma23
Hashtags:
#AI #ModelCompression #AIoptimization #DeepLearning #MachineLearning #Quantization #Pruning #KnowledgeDistillation #EfficientAI #EdgeAI #TinyML #LLM #ArtificialIntelligence #TechExplained #AINews #AIOptimization #EdgeAI #Quantization #PruningAI #EfficientAI #AIOnEdge #LLMCompression



Comments
Post a Comment